

해당 시리즈는 '인터프리터 만들기 with go' 책을 처음부터 하나씩 따라가며 인터프리터를 구현한 내용을 담았다. 따라서 앞으로 나올 모든 코드는 책의 내용을 직접 따라치며 구현한 결과이다. 시리즈의 목적은 단순 구현이 아닌 이 과정에서 마주친 의문점들에 대해 탐구하고 해결해나가는 과정을 통해, 인터프리터의 동작 원리를 제대로 이해하는 것이다.

렉서에 대해 알아보기 전에 우선 인터프리터에 대해 알아보자.
인터프리터
인터프리터란?
인터프리터(Interpreter)는 소스 코드를 직접 실행하는 프로그램이다. 컴파일러처럼 기계어로 번역하지 않고, 코드를 읽으면서 즉시 해석하고 실행한다.
컴파일러 vs 인터프리터
컴파일러: 소스 코드 → [번역] → 실행 파일 → 실행
인터프리터: 소스 코드 → [해석 + 실행] → 결과
인터프리터 전체 구조
우리가 구현해볼 인터프리터는 크게 4가지로 구성되어 있다.
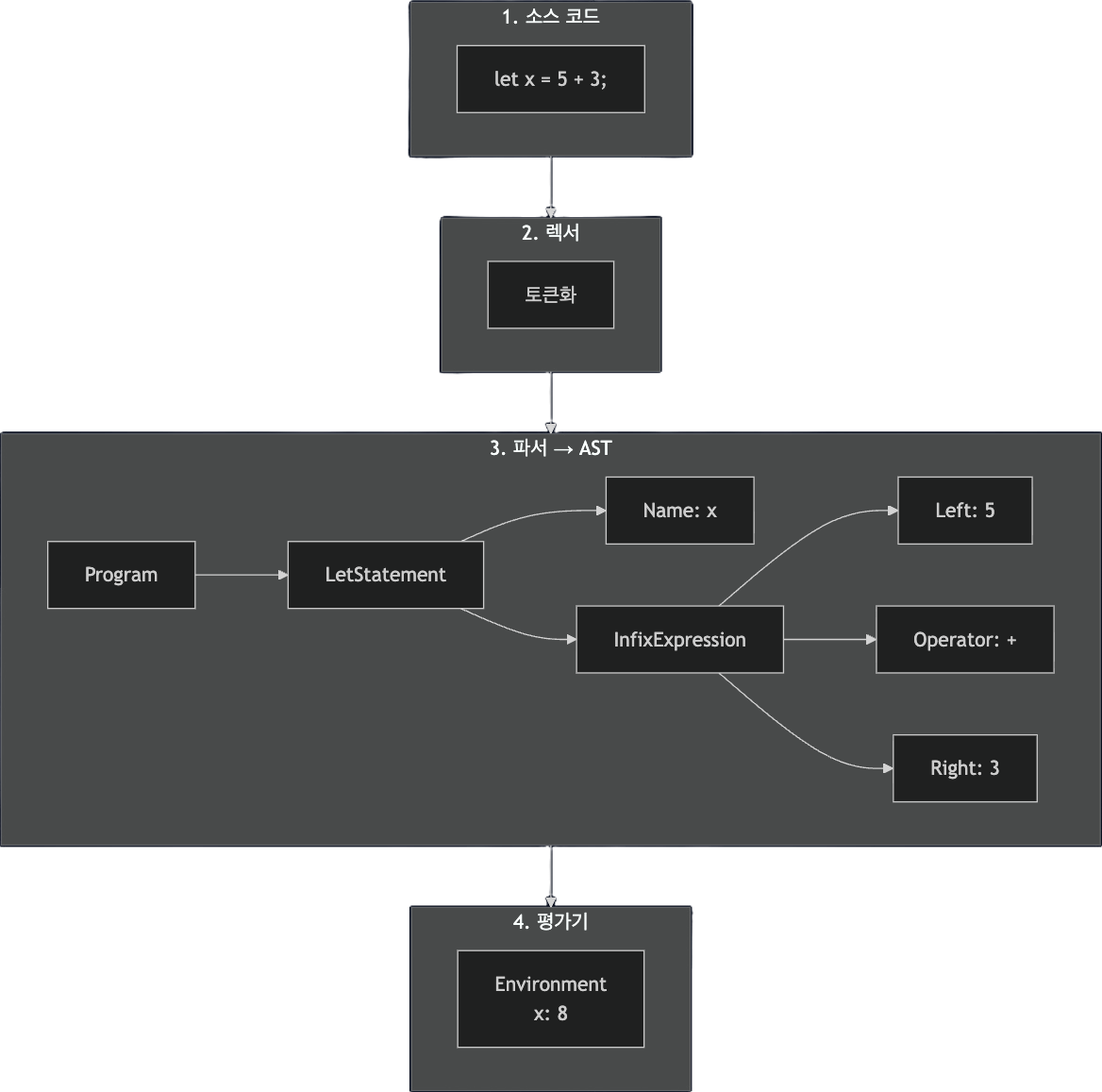
소스 코드가 실행되기까지 4단계 과정
1. 렉서(Lexer): 문자 → 토큰
2. 파서(Parser): 토큰 → AST
3. 평가기(Evaluator): AST → 실행
4. 결과 출력
이번 글에서는 1단계 렉서에 대해 다뤄볼 것이다.
렉서 구현에 들어가기에 앞서
"소스 코드를 토큰으로 변환한다"
책에서 위 문장을 읽었을 때는 이해했다고 생각했다. 토큰화를 해야 우리의 소스코드를 인터프리터가 이해할 것이지 않은가. 하지만 막상 구현하려니 막막한 기분이 들었다. 'let x = 5;'라는 문자열을 어떻게 'LET', 'IDENT', 'ASSIGN'으로 나눌까? 공백은 어떻게 처리하지?
이 글은 렉서를 구현하며 마주한 문제들과 해결 과정을 기록한다.
토큰의 역할
토큰은 렉서가 만드는 결과물이다. 토큰을 통해서 소스코드를 토큰화하여 어휘를 분석한다. 밑바닥부터 인터프리터 만들기 책에 따르면 "토큰은 프로그래밍 언어의 최소 의미 단위입니다."라고 나와있다. 최소 의미 단위가 무슨 말일까?
토큰은 최소 의미 단위?
아래 코드를 예시로 들어보자. 어떻게 토큰화(의미있는 단위)를 할 수 있을까?
let x = 5
let과 x, 등호와 숫자 5 모두 분리해야 하지 않을까? 우선 눈이 보이는대로 모두 나누어보았다.
"let" / " " / "x" / " " / "=" / " " / "5"
그런데 한 가지 의문점이 있다. 공백도 의미있는 단위일까?🤔 공백은 구분자이지 않을까? 그러면 공백을 제거해보자.
"let" / "x" / "=" / "5"
분석했던 것처럼 조금 더 의미있는 단위로 나뉜 것 같지 않은가? let은 어떤 한 변수의 타입을 의미하고, x는 변수의 이름을 의미하고, 등호는 좌항과 우항이 같음을 의미하고, 이로써 변수 x는 5라는 것을 의미한다.
토큰화
이제 대략적인 분석이 끝났다. 위 단위를 토대로 아래와 같이 토큰의 타입을 정의해보았다. 꽤 그럴듯 하다. 이로써 토큰 정의가 끝난걸까?
const (
LET = "LET"
IDENT = "IDENT"
ASSIGN = "="
INT = "INT"
)
그렇지 않다. 실제로 이 토큰들을 사용해 렉서를 구현하기 위해서는, 아래와 같이 구조체를 정의해줘야 한다.
type Token struct {
Type TokenType
Literal string
}
Literal의 필요성
Type은 우리가 정의한 토큰들이다. 그런데 Literal은 어떤 것을 의미하는걸까? 왜 필요하지?
- Type: 무슨 종류인지
- Literal: 실제로 값이 뭔지
사실 같은 타입이라도 여러 값이 존재할 수 있다. 아래 코드는 예시이다.
let x = 10
let y = 5
위 코드를 토큰화 하면 아래와 같이 분석할 수 있다. 이처럼 우리는 실제로 토큰의 값을 알아야하기 때문에 Literal이 필요한 것이다.
Token{Type: LET, Literal: "let"}
Token{Type: IDENT, Literal: "x"}
Token{Type: ASSIGN, Literal: "="}
Token{Type: INT, Literal: "10"}
Token{Type: LET, Literal: "let"}
Token{Type: IDENT, Literal: "y"}
Token{Type: ASSIGN, Literal: "="}
Token{Type: INT, Literal: "5"}
왜 position과 readPosition을 따로 관리할까?
그런데 Lexer 구조체를 정의하면서 의문이 들었다. 왜 position과 readPosition 2개가 필요할까? position 하나로만 관리할수는 없을까?
type Lexer struct {
input string
position int
readPosition int
ch byte
}
1) position만 사용한다면?
position만 사용한다면 코드는 아래와 같다.
Lexer 구조체
type Lexer struct {
input string
position int
ch byte
}
readChar() 함수
func (l *Lexer) readChar() {
l.position++
if l.position >= len(l.input) {
l.ch = 0
} else {
l.ch = l.input[l.position]
}
}
peekChar() 함수
func (l *Lexer) peekChar() byte {
if l.position + 1 >= len(l.input) {
return 0
} else {
return l.input[l.position + 1]
}
}
테스트를 통해 검증해보자.
func TestNextToken(t *testing.T) {
input := `let x = 5;`
tests := []struct {
expectedType token.TokenType
expectedLiteral string
}{
{token.LET, "let"},
{token.IDENT, "x"},
{token.ASSIGN, "="},
{token.INT, "5"},
{token.SEMICOLON, ";"},
}
l := New(input)
for i, tt := range tests {
tok := l.NextToken()
if tok.Type != tt.expectedType {
t.Fatalf("tests[%d] - tokentype wrong. expected=%q, got=%q", i, tt.expectedType, tok.Type)
}
if tok.Literal != tt.expectedLiteral {
t.Fatalf("tests[%d] - literal wrong. expected=%q, got=%q", i, tt.expectedLiteral, tok.Literal)
}
}
}
실행 결과
% go test ./lexer
--- FAIL: TestNextToken (0.00s)
lexer_test.go:28: tests[0] - tokentype wrong. expected="LET", got="IDENT"
테스트가 실패한다. 테스트 결과에 따르면 토큰 타입 "LET"을 기대했지만, "IDENT"를 얻었다는 것을 확인할 수 있다. 그 이유는 아래와 같다.

readChar() 함수가 실행되면 맨 처음에 position++이 실행된다. 이로 인해 0번째 인덱스의 'l'을 읽기도 전에 position이 1로 증가해버린다. 결국 'e'부터 읽기 시작하게 되고, "et"가 인식된다. "et"는 우리가 정의한 키워드가 아니기 때문에 일반 식별자(IDENT)로 분류된다. 우리가 기대했던 "let" (LET) 대신 "et" (IDENT)를 얻게 된 이유다.
2) position과 readPosition을 따로 관리한다면?
Lexer 구조체
type Lexer struct {
input string
position int
readPosition int
ch byte
}
readChar() 함수
func (l *Lexer) readChar() {
if l.readPosition >= len(l.input) {
l.ch = 0
} else {
l.ch = l.input[l.readPosition]
}
l.position = l.readPosition
l.readPosition += 1
}
peekChar() 함수
func (l *Lexer) peekChar() byte {
if l.readPosition >= len(l.input) {
return 0
} else {
return l.input[l.readPosition]
}
}

초기 상태에서는 position과 readPosition 모두 0이다. readChar()가 호출되면, 먼저 ch = input[readPosition]을 통해 현재 readPosition 위치의 문자를 읽는다. 이때 input[0]인 'l'이 ch에 저장된다. 그 다음 position = readPosition으로 현재 위치를 동기화하고, 마지막으로 readPosition++으로 다음에 읽을 위치를 1로 증가시킨다. 이렇게 하면 첫 문자 'l'을 건너뛰지 않고 정확히 읽을 수 있다.
결론
position만 사용하는 방식은 위치를 먼저 증가시킨 후 문자를 읽기 때문에 첫 문자를 건너뛰는 문제가 발생한다.
반면 readPosition을 함께 사용하면 현재 위치의 문자를 먼저 읽고, 그 다음 위치를 업데이트하기 때문에 모든 문자를 정확히 읽을 수 있다. readPosition은 단순히 "다음에 읽을 위치"를 미리 준비해두는 역할을 하며, 이를 통해 "읽되 이동하지 않기"가 가능해진다.
peekChar()은 왜 필요할까? readChar()만 있으면 안되나?
우선 readChar()만 사용한 코드는 아래와 같다.
1) readChar()만 사용
NextToken()
func (l *Lexer) NextToken() token.Token {
var tok token.Token
l.skipWhitespace()
switch l.ch {
case '=':
l.readChar()
if l.ch == '=' {
tok = token.Token{Type: token.EQ, Literal: "=="}
} else {
tok = newToken(token.ASSIGN, '=')
}
case '!':
l.readChar()
if l.ch == '=' {
tok = token.Token{Type: token.NOT_EQ, Literal: "!="}
} else {
tok = newToken(token.BANG, '!')
}
case 0:
tok.Literal = ""
tok.Type = token.EOF
default:
if isLetter(l.ch) {
tok.Literal = l.readIdentifier()
tok.Type = token.LookupIdent(tok.Literal)
return tok
} else if isDigit(l.ch) {
tok.Type = token.INT
tok.Literal = l.readNumber()
return tok
} else {
tok = newToken(token.ILLEGAL, l.ch)
}
}
l.readChar()
return tok
}
테스트코드
func TestNextToken(t *testing.T) {
input := `5 = 10
5 == 10
5 != 10
!5`
tests := []struct {
expectedType token.TokenType
expectedLiteral string
}{
// "5 = 10"
{token.INT, "5"},
{token.ASSIGN, "="},
{token.INT, "10"},
// "5 == 10"
{token.INT, "5"},
{token.EQ, "=="},
{token.INT, "10"},
// "5 != 10"
{token.INT, "5"},
{token.NOT_EQ, "!="},
{token.INT, "10"},
// "!5"
{token.BANG, "!"},
{token.INT, "5"},
{token.EOF, ""},
}
l := New(input)
for i, tt := range tests {
tok := l.NextToken()
fmt.Printf("Token: %s, Next position: %d, Next ch: '%c'\n", tok.Type, l.position, l.ch)
if tok.Type != tt.expectedType {
t.Fatalf("tests[%d] - tokentype wrong. expected=%q, got=%q",
i, tt.expectedType, tok.Type)
}
if tok.Literal != tt.expectedLiteral {
t.Fatalf("tests[%d] - literal wrong. expected=%q, got=%q",
i, tt.expectedLiteral, tok.Literal)
}
}
}
실행 결과
% go test ./lexer
Token: INT, Next position: 1, Next ch: ' '
Token: =, Next position: 4, Next ch: '1'
Token: INT, Next position: 6, Next ch: ' '
Token: INT, Next position: 9, Next ch: ' '
Token: ==, Next position: 12, Next ch: ' '
Token: INT, Next position: 15, Next ch: ' '
Token: INT, Next position: 18, Next ch: ' '
Token: !=, Next position: 21, Next ch: ' '
Token: INT, Next position: 24, Next ch: ' '
Token: !, Next position: 28, Next ch: ''
Token: EOF, Next position: 29, Next ch: ''
--- FAIL: TestNextToken (0.00s)
lexer_test.go:49: tests[10] - tokentype wrong. expected="INT", got="EOF"
테스트 실행 결과를 살펴보면 케이스가 "!5"일 때, 실패하는 것을 볼 수 있다. 그 이유를 살펴보자.

case '!'에 진입하면, readChar()을 호출해 다음 문자가 '='인지 확인한다. 이때 position이 1로 이동하면서 ch는 '5'가 된다. '='가 아니므로 BANG 토큰을 생성하는데, 여기서 문제가 발생한다.
토큰을 반환하기 전에 readChar()가 한 번 더 실행되면서 position이 2로 이동하고, '5'를 건너뛰고 EOF에 도달해버린다. 결국 '5'는 확인만 했을 뿐 사용하지 않았지만, readChar()의 특성상 읽으면서 동시에 이동하기 때문에 '5'를 잃어버리게 된다.
다른 케이스들은 왜 성공했을까? "!="의 경우 readChar()로 읽은 '='를 토큰에 실제로 사용했기 때문에, return 전의 추가 readChar()가 다음 문자로 정상 이동했다. 하지만 "!5"는 '5'를 확인만 하고 사용하지 않았기 때문에 문제가 발생한 것이다.
2) peekChar() 함께 사용
이제 peekChar()를 추가한 코드로 다시 작성해보자.
NextToken()
func (l *Lexer) NextToken() token.Token {
var tok token.Token
l.skipWhitespace()
switch l.ch {
case '=':
if l.peekChar() == '=' {
ch := l.ch
l.readChar()
literal := string(ch) + string(l.ch)
tok = token.Token{Type: token.EQ, Literal: literal}
} else {
tok = newToken(token.ASSIGN, l.ch)
}
case '!':
if l.peekChar() == '=' {
ch := l.ch
l.readChar()
literal := string(ch) + string(l.ch)
tok = token.Token{Type: token.NOT_EQ, Literal: literal}
} else {
tok = newToken(token.BANG, l.ch)
}
case 0:
tok.Literal = ""
tok.Type = token.EOF
default:
if isLetter(l.ch) {
tok.Literal = l.readIdentifier()
tok.Type = token.LookupIdent(tok.Literal)
return tok
} else if isDigit(l.ch) {
tok.Type = token.INT
tok.Literal = l.readNumber()
return tok
} else {
tok = newToken(token.ILLEGAL, l.ch)
}
}
l.readChar()
return tok
}
실행 결과
% go test ./lexer
ok github.com/Jihyun3478/logi-lang/lexer 0.408s
테스트가 통과한다. 왜 통과했을까?

peekChar()는 readChar()와 달리 다음 문자를 확인만 하고 position을 이동시키지 않는다. "!5"를 처리할 때, peekChar()로 다음 문자가 '='인지 확인한다. 이때 position은 여전히 0이고, ch는 '!'인 상태를 유지한다. '='가 아니므로 BANG 토큰을 생성하고, return 전에 readChar()가 호출되면서 position이 1로 이동하고 ch는 '5'가 된다.
이제 '5'를 정상적으로 읽을 수 있다. peekChar()는 "읽되 이동하지 않기"를 가능하게 한다. 특히 ==, != 같은 2문자 토큰을 인식할 때, 다음 문자를 미리 확인하면서도 현재 위치를 유지할 수 있어 필수적이다.
결론
readChar()만으로는 "다음 문자 확인"과 "위치 이동"을 분리할 수 없다. peekChar()는 이 두 가지를 분리해, 다음 문자를 확인하되 실제로 사용하지 않을 경우에도 안전하게 처리할 수 있게 해준다.
공백 처리
공백도 토큰일까?
프로그래밍 언어에서 아래 세 코드는 모두 같은 의미일까?
let x = 5
let x = 5
let x = 5
대부분의 프로그래밍 언어에서 공백의 개수는 중요하지 않다. 공백은 단어를 구분하는 역할만 할 뿐, 그 자체로 의미를 갖지 않는다. 그렇다면 공백도 토큰으로 만들어야 할까? 아니면 무시해야 할까?
skipWhitespace() 없이 테스트
공백을 처리하지 않으면 어떻게 될까? skipWhitespace()를 주석 처리하고 테스트해보자.
NextToken()
func (l *Lexer) NextToken() token.Token {
var tok token.Token
// l.skipWhitespace()
switch l.ch {
case '=':
if l.peekChar() == '=' {
ch := l.ch
l.readChar()
literal := string(ch) + string(l.ch)
tok = token.Token{Type: token.EQ, Literal: literal}
} else {
tok = newToken(token.ASSIGN, l.ch)
}
case '!':
if l.peekChar() == '=' {
ch := l.ch
l.readChar()
literal := string(ch) + string(l.ch)
tok = token.Token{Type: token.NOT_EQ, Literal: literal}
} else {
tok = newToken(token.BANG, l.ch)
}
case 0:
tok.Literal = ""
tok.Type = token.EOF
default:
if isLetter(l.ch) {
tok.Literal = l.readIdentifier()
tok.Type = token.LookupIdent(tok.Literal)
return tok
} else if isDigit(l.ch) {
tok.Type = token.INT
tok.Literal = l.readNumber()
return tok
} else {
tok = newToken(token.ILLEGAL, l.ch)
}
}
l.readChar()
return tok
}
func isLetter(ch byte) bool {
return 'a' <= ch && ch <= 'z' || 'A' <= ch && ch <= 'Z' || ch == '_'
}
func isDigit(ch byte) bool {
return '0' <= ch && ch <= '9'
}
실행 결과
% go test ./lexer
--- FAIL: TestNextToken (0.00s)
lexer_test.go:124: tests[1] - tokentype wrong. expected="IDENT", got="ILLEGAL"
공백 문자(' ')가 switch문의 어떤 case에도 해당하지 않아 default로 가게 된다. 공백은 문자도 아니고(isLetter) 숫자도 아니기(isDigit) 때문에 ILLEGAL 토큰이 생성된다.
공백을 토큰으로 만든다면?
그렇다면 공백을 하나의 토큰으로 만들면 어떨까?
case ' ':
tok = newToken(token.WHITESPACE, l.ch)
파서가 토큰을 분석할 때, 이 수많은 공백 토큰들을 모두 처리해야 한다. 공백은 의미가 없는데도 매번 확인하고 건너뛰어야 하므로 비효율적이다.
skipWhitespace()
공백은 토큰으로 만들지 않고, 아예 건너뛰는 것이 효율적이다.
왜 필요한가?
공백, 탭, 개행 등은 코드의 가독성을 위해 존재할 뿐, 프로그램의 동작에는 영향을 주지 않는다. 따라서 토큰화 단계에서 미리 제거하는 것이 좋다.
언제 호출하는가?
NextToken()이 호출될 때마다 가장 먼저 실행된다. 현재 문자가 공백이면 의미 있는 문자가 나올 때까지 계속 건너뛴다.
func (l *Lexer) NextToken() token.Token {
var tok token.Token
l.skipWhitespace()
switch l.ch {
// ...
}
}
어떤 문자들을 처리하는가?
func (l *Lexer) skipWhitespace() {
for l.ch == ' ' || l.ch == '\t' || l.ch == '\n' || l.ch == '\r' {
l.readChar()
}
}
- ' '(공백): 가장 일반적인 공백 문자
- '\t'(탭): 들여쓰기에 사용
- '\n'(개행): 줄 바꿈
- '\r'(캐리지 리턴): Windows 스타일 줄 바꿈
이 모든 문자들은 "의미 없는 공백"으로 취급되어 토큰화 과정에서 무시된다.
동작 과정

이제 skipWhitespace() 덕분에 공백의 개수와 관계없이 올바른 토큰을 생성할 수 있다.
정리
렉서 구현 과정에서 세 가지 핵심을 확인했다.
- position과 readPosition 분리: "현재 위치"와 "다음 위치"를 동시에 추적하기 위해 필요하다.
- peekChar()의 필요성: "읽되 이동하지 않기"를 통해 2문자 토큰(==, !=)을 안전하게 처리할 수 있다.
- skipWhitespace()의 역할: 의미 없는 공백 문자들을 미리 제거해 효율적인 토큰화를 가능하게 한다.
이 세 가지가 모두 갖춰져야 비로소 완전한 렉서가 완성된다.
렉서 전체 코드
token.go
package token
type TokenType string
type Token struct {
Type TokenType
Literal string
}
const (
ILLEGAL = "ILLEGAL"
EOF = "EOF"
IDENT = "IDENT"
INT = "INT"
ASSIGN = "="
PLUS = "+"
MINUS = "-"
BANG = "!"
ASTERISK = "*"
SLASH = "/"
LT = "<"
GT = ">"
EQ = "=="
NOT_EQ = "!="
COMMA = ","
SEMICOLON = ";"
LPAREN = "("
RPAREN = ")"
LBRACE = "{"
RBRACE = "}"
FUNCTION = "FUNCTION"
LET = "LET"
TRUE = "TRUE"
FALSE = "FALSE"
IF = "IF"
ELSE = "ELSE"
RETURN = "RETURN"
)
var keywords = map[string]TokenType{
"fn": FUNCTION,
"let": LET,
"true": TRUE,
"false": FALSE,
"if": IF,
"else": ELSE,
"return": RETURN,
}
// 주어진 식별자가 예약어(키워드)인지 확인하고, 예약어면 해당 토큰 타입을, 아니면 IDENT를 반환
func LookupIdent(ident string) TokenType {
if tok, ok := keywords[ident]; ok {
return tok
}
return IDENT
}
lexer.go
package lexer
import (
"github.com/Jihyun3478/logi-lang/token"
)
// 소스 코드를 토큰으로 변환하는 렉서
type Lexer struct {
input string
position int // 입력에서 현재 위치(현재 문자를 가리킴)
readPosition int // 입력에서 현재 읽는 위치(현재 문자의 다음을 가리킴)
ch byte // 현재 조사하고 있는 문자
}
// 주어진 입력으로 새 렉서를 생성하고 첫 문자를 읽음
func New(input string) *Lexer {
l := &Lexer{input: input}
l.readChar()
return l
}
// 현재 문자를 검사하여 해당하는 토큰을 반환하고 다음 문자로 이동
func (l *Lexer) NextToken() token.Token {
var tok token.Token
l.skipWhitespace()
switch l.ch {
case '=':
if l.peekChar() == '=' {
ch := l.ch
l.readChar()
literal := string(ch) + string(l.ch)
tok = token.Token{Type: token.EQ, Literal: literal}
} else {
tok = newToken(token.ASSIGN, l.ch)
}
case '+':
tok = newToken(token.PLUS, l.ch)
case '-':
tok = newToken(token.MINUS, l.ch)
case '!':
if l.peekChar() == '=' {
ch := l.ch
l.readChar()
literal := string(ch) + string(l.ch)
tok = token.Token{Type: token.NOT_EQ, Literal: literal}
} else {
tok = newToken(token.BANG, l.ch)
}
case '/':
tok = newToken(token.SLASH, l.ch)
case '*':
tok = newToken(token.ASTERISK, l.ch)
case '<':
tok = newToken(token.LT, l.ch)
case '>':
tok = newToken(token.GT, l.ch)
case ';':
tok = newToken(token.SEMICOLON, l.ch)
case ',':
tok = newToken(token.COMMA, l.ch)
case '(':
tok = newToken(token.LPAREN, l.ch)
case ')':
tok = newToken(token.RPAREN, l.ch)
case '{':
tok = newToken(token.LBRACE, l.ch)
case '}':
tok = newToken(token.RBRACE, l.ch)
case 0:
tok.Literal = ""
tok.Type = token.EOF
default:
if isLetter(l.ch) {
tok.Literal = l.readIdentifier()
tok.Type = token.LookupIdent(tok.Literal)
return tok
} else if isDigit(l.ch) {
tok.Type = token.INT
tok.Literal = l.readNumber()
return tok
} else {
tok = newToken(token.ILLEGAL, l.ch)
}
}
l.readChar()
return tok
}
// 문자가 알파벳이거나 언더바(_)인지 확인
func isLetter(ch byte) bool {
return 'a' <= ch && ch <= 'z' || 'A' <= ch && ch <= 'Z' || ch == '_'
}
// 주어진 타입과 문자로 새 토큰을 생성
func newToken(tokenType token.TokenType, ch byte) token.Token {
return token.Token{Type: tokenType, Literal: string(ch)}
}
// 연속된 문자들을 읽어 식별자(변수명, 키워드 등)를 반환
func (l *Lexer) readIdentifier() string {
position := l.position
for isLetter(l.ch) {
l.readChar()
}
return l.input[position:l.position]
}
// 다음 문자를 읽고 입력에서 위치를 전진시킨 후 EOF이면 0을 설정
func (l *Lexer) readChar() {
if l.readPosition >= len(l.input) {
l.ch = 0
} else {
l.ch = l.input[l.readPosition]
}
l.position = l.readPosition
l.readPosition += 1
}
func (l *Lexer) peekChar() byte {
if l.readPosition >= len(l.input) {
return 0
} else {
return l.input[l.readPosition]
}
}
// 백, 탭, 개행 등 whitespace 문자들을 건너뜀
func (l *Lexer) skipWhitespace() {
for l.ch == ' ' || l.ch == '\t' || l.ch == '\n' || l.ch == '\r' {
l.readChar()
}
}
// 연속된 숫자들을 읽어 숫자 리터럴 문자열을 반환
func (l *Lexer) readNumber() string {
position := l.position
for isDigit(l.ch) {
l.readChar()
}
return l.input[position:l.position]
}
// 문자가 숫자(0-9)인지 확인
func isDigit(ch byte) bool {
return '0' <= ch && ch <= '9'
}
lexer_test.go
package lexer
import (
"testing"
"github.com/Jihyun3478/logi-lang/token"
)
func TestNextToken(t *testing.T) {
input := `let five = 5;
let ten = 10;
let add = fn(x, y) {
x + y;
};
let result = add(five, ten);
!-/*5;
5 < 10 > 5;
if (5 < 10) {
return true;
} else {
return false;
}
10 == 10;
10 != 9;
`
tests := []struct {
expectedType token.TokenType
expectedLiteral string
}{
{token.LET, "let"},
{token.IDENT, "five"},
{token.ASSIGN, "="},
{token.INT, "5"},
{token.SEMICOLON, ";"},
{token.LET, "let"},
{token.IDENT, "ten"},
{token.ASSIGN, "="},
{token.INT, "10"},
{token.SEMICOLON, ";"},
{token.LET, "let"},
{token.IDENT, "add"},
{token.ASSIGN, "="},
{token.FUNCTION, "fn"},
{token.LPAREN, "("},
{token.IDENT, "x"},
{token.COMMA, ","},
{token.IDENT, "y"},
{token.RPAREN, ")"},
{token.LBRACE, "{"},
{token.IDENT, "x"},
{token.PLUS, "+"},
{token.IDENT, "y"},
{token.SEMICOLON, ";"},
{token.RBRACE, "}"},
{token.SEMICOLON, ";"},
{token.LET, "let"},
{token.IDENT, "result"},
{token.ASSIGN, "="},
{token.IDENT, "add"},
{token.LPAREN, "("},
{token.IDENT, "five"},
{token.COMMA, ","},
{token.IDENT, "ten"},
{token.RPAREN, ")"},
{token.SEMICOLON, ";"},
{token.BANG, "!"},
{token.MINUS, "-"},
{token.SLASH, "/"},
{token.ASTERISK, "*"},
{token.INT, "5"},
{token.SEMICOLON, ";"},
{token.INT, "5"},
{token.LT, "<"},
{token.INT, "10"},
{token.GT, ">"},
{token.INT, "5"},
{token.SEMICOLON, ";"},
{token.IF, "if"},
{token.LPAREN, "("},
{token.INT, "5"},
{token.LT, "<"},
{token.INT, "10"},
{token.RPAREN, ")"},
{token.LBRACE, "{"},
{token.RETURN, "return"},
{token.TRUE, "true"},
{token.SEMICOLON, ";"},
{token.RBRACE, "}"},
{token.ELSE, "else"},
{token.LBRACE, "{"},
{token.RETURN, "return"},
{token.FALSE, "false"},
{token.SEMICOLON, ";"},
{token.RBRACE, "}"},
{token.INT, "10"},
{token.EQ, "=="},
{token.INT, "10"},
{token.SEMICOLON, ";"},
{token.INT, "10"},
{token.NOT_EQ, "!="},
{token.INT, "9"},
{token.SEMICOLON, ";"},
{token.EOF, ""},
}
l := New(input)
for i, tt := range tests {
tok := l.NextToken()
if tok.Type != tt.expectedType {
t.Fatalf("tests[%d] - tokentype wrong. expected=%q, got=%q", i, tt.expectedType, tok.Type)
}
if tok.Literal != tt.expectedLiteral {
t.Fatalf("tests[%d] - literal wrong. expected=%q, got=%q", i, tt.expectedLiteral, tok.Literal)
}
}
}
참고자료
아래 링크를 클릭하면 책의 전체 코드를 다운받을 수 있다.
'Project > 밑바닥부터 만드는 인터프리터 in go' 카테고리의 다른 글
| [밑바닥부터 만드는 인터프리터 in go] 3. 평가기 동작 원리 (0) | 2025.11.19 |
|---|---|
| [밑바닥부터 만드는 인터프리터 in go] 2. 파서 동작 원리 (0) | 2025.11.18 |